OpenSource4You is an active community in Taiwan contributing to large-scale open source software
Starting from the following time and location, chungen and I will take turns hosting the Ozone Chinese Meeting
- Time: Every Monday 22:00-23:00 (Taiwan Time UTC+8) starting July 14th 2025
- Location (Virtual): https://opensource4you.tw/ozone/meeting
- Calendar: https://calendar.opensource4you.tw
If you’re interested in Ozone technical updates or contributing to Ozone itself Welcome to join the Ozone meeting!
Introduction#
This series is expected to have three parts detailing the principles and details of Ozone Snapshot:
- Part 1 will first introduce the basic structure of Ozone Snapshot as well as Snapshot Deep Clean & Reclaimable Filter. It mainly explains how Ozone solves the problem of avoiding deletion of user-visible data in snapshots and how the deletion service efficiently removes invisible data from the entire cluster.
- Part 2 will introduce Snapshot Diff, the most important feature in Snapshot. It mainly explains how Snapshot Diff overcomes compaction churn and tracks SST changes to calculate changes between any two snapshots -
+(add),-(delete),M(modify),R(rename). - Part 3 will also be related to snapshot cleanup, but while Part 1 focuses on data cleanup on datanodes, this part will explore how to use SST Files Filtering on Ozone Manager to remove data (SST Files) unrelated to each Snapshot, and how Snapshot Deleting Service handles snapshot-aware reclaimable resource cases when deleting snapshots.
After reading this article, you will understand:
- How Ozone ensures data in Snapshots is not mistakenly deleted, guaranteeing data consistency
- How the Deletion Service and Deep Clean mechanism efficiently reclaim invisible data and free up storage space
- How the Reclaimable Filter achieves snapshot-aware precise reclamation, avoiding accidental deletion of still-referenced resources
Ozone Basic#
Apache Ozone is an open source distributed file system
Ozone manages file/object metadata through one of its components called Ozone Manager. From the client’s perspective, the process is:
- Query Ozone Manager for
red-uncle.png - The client receives a response indicating which blocks compose this file’s content
- The client asks Storage Container Manager about the locations of these blocks on Data Nodes
- After knowing which Data Nodes to read from, the client requests file content according to the file sequence
- Perfect
Storage Container Manager a.k.a. SCM, is the boss of all Data Nodes, responsible for commanding Data Nodes to work, including deleting data blocks. As for Data Node, it stores a bunch of data blocks, which are the actual file contents. A group of consecutive data blocks forms a unit called Container, not the Linux Container… But that’s not today’s focus. If you want to learn about this part, feel free to leave a comment asking me to write an article about it haha
Haha, we’ve covered Ozone’s entire architecture in just a few sentences. Ozone Manager manages file/key/directory metadata (name, size, data blocks location), Data Node stores the actual file data/content scattered across nodes, and Storage Container Manager is the boss of all Data Nodes
Snapshot Brief#
Ozone Snapshot is a powerful feature on Ozone Manager. As its name suggests, it captures the state of file metadata at a specific moment. You can query metadata within any Snapshot, and more powerfully, you can specify any two Snapshots and ask Ozone to tell you what changed between them, enabling features like Cross-Region Replication through Ozone Snapshot.
Ozone Snapshot implementation mainly relies on RocksDB’s Checkpoint feature. RocksDB Checkpoint is an efficient data snapshot mechanism provided by RocksDB. Its core principle is: quickly generating a “consistent snapshot” of the database’s current state without copying data. This snapshot is essentially a new data directory where most files point to the original SST Files through hard links, making it extremely fast to create and requiring no additional space.
The Challenge#
Hey, implementing Ozone Snapshot doesn’t sound that hard? But there’s no free lunch - supporting Snapshot brings additional complexity and challenges to the system, and modern problems require modern solutions.
Since Snapshot allows users to directly read keys within a snapshot, suppose key1 in a snapshot is still readable, but deletion on AOS causes the data on Data Node to be deleted. This would make it unintuitive when users try to read key1 from that snapshot, only to find they can’t read its data blocks’ content, right?
This brings us to how Ozone handles deleted key/file/directory records on Ozone Manager:
When deleting key/file/directory, Ozone doesn’t delete directly but first records them in deletedTable and deletedDirectoryTable RocksDB column families a.k.a Tables. Then background services - KeyDeletingService & DirectoryDeletingService - pick up items from those tables storing deleted key/file/dir and tell Storage Container Manager to delete the corresponding data blocks.
This mechanism raises two problems to solve, which are the focus of this article:
- Items in
deletedTable/deletedDirectoryTablewithin snapshots haven’t been cleaned up!! DataNodes still store a bunch of data blocks invisible to clients… This corresponds to DeletingService / Deep Clean - When DeletingService looks at data blocks to submit for batch deletion to SCM, it can’t blindly submit everything. It needs to be Snapshot-Aware, filtering out data blocks owned by keys/files visible in snapshots to avoid deleting them, like filtering impurities. This corresponds to Reclaimable Filter
Note: Seeing the first point, you might think: aren’t the items in deletedTable/deletedDirectoryTable still in the db? Can’t we just let DeletingService clean them up?
That’s not wrong, but considering the snapshot-aware problem, if DeletingService checks deletedTable/deletedDirectoryTable for keys/files/dirs, it would have to check all snapshots to see if they contain that key/file/dir. That’s very inefficient.
So Ozone optimizes this by, at snapshot creation time, cleaning all deleted records from deletedTable/deletedDirectoryTable in the AOS, leaving only those deleted records in the snapshot itself.
Then, DeletingService only needs to check each snapshot’s deletedTable/deletedDirectoryTable and compare with the previous snapshot to see if those items are present.
This way, DeletingService doesn’t have to scan the entire snapshot each time it cleans up.
It’s like amortizing the process of checking whether a key can be reclaimed across all snapshots.
Detailed Introduction to Snapshot Feature#
The official website teaches you how to use Ozone Snapshot: Ozone Snapshot
There are also several articles explaining what Ozone snapshot can do in detail, if you’re interested:
Introducing Apache Ozone Snapshots: Introduces Ozone, the uses of Ozone Snapshot, and mentions Cloudera’s own Replication Manager that can leverage Ozone Snapshot for multi-cluster data replication
Object Stores: The Case for Snapshots vs Object Versioning: Compares Ozone Snapshot with traditional “Object Versioning”. While object versioning can preserve multiple versions of each object for easy recovery or rollback, it brings management challenges like Namespace Explosion, GC for Versions, and Referential Integrity and Consistency, especially prone to state inconsistencies when applications have dependencies. Ozone’s Snapshot feature creates application-consistent, read-only snapshots of entire object groups (like a bucket) at specific points in time, avoiding issues with excessive versions and maintenance difficulties while naturally ensuring data integrity and application consistency. This makes applications more reliable and simple when restoring historical states while significantly reducing management burden.
Exploring Apache Ozone Snapshots: Briefly introduces Ozone Snapshot features: (1) Supports user snapshot operations at the bucket level, allowing you to quickly freeze and preserve a bucket’s state at any moment. (2) Snapshot operations complete instantly and can be accessed directly through dedicated filesystem paths. (3) Users can list all snapshots, compare differences between snapshots (Snapshot Diff), and even restore data from snapshots. (4) Snapshots are read-only, can be deleted independently, and won’t be affected by main storage data deletion.
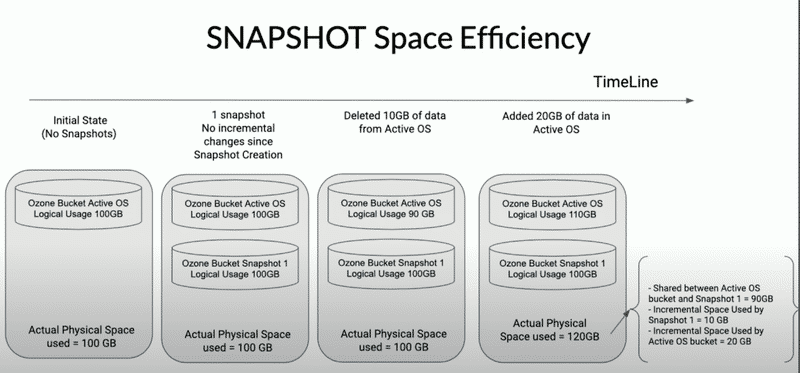
Space usage grows based on actual differences between snapshots, without duplicating unchanged parts.
Apache Ozone Snapshots: Addressing Different Use Cases: Various Snapshot Use Cases including: Data Protection (Failed Transactions, Ransomware, Malware State), Time Travel, Data Replication and Remote Replication, Archival and Compliance, Incremental Analytics and Generative AI (hmm?)
Apache Ozone Using the Snapshot Feature: Teaches you how to CRUD Snapshots, Snapshot Rename, and Snapshot Diff in Ozone
Ozone Snapshot Basic#
Metadata of Snapshot#
Snapshot Info#
Ozone uses SnapshotInfo as metadata for each Snapshot:
SnapshotInfo primarily records various information about each snapshot, including its UUID, name, volume and bucket it belongs to, and current status (such as ACTIVE or DELETED). Additionally, it contains creation and deletion times, associations with previous snapshots (whether under the same bucket path or globally), RocksDB checkpoint directory and sequence number, as well as data-related statistics such as the snapshot’s referenced data size, storage space after considering replication or Erasure Coding, and the exclusive data amount for that snapshot. Finally, it also records whether deep cleaning, SST file filtering, and deletedDirectoryTable deep clean have been performed. All this information is persisted in OM’s RocksDB.
Snapshot Chain#
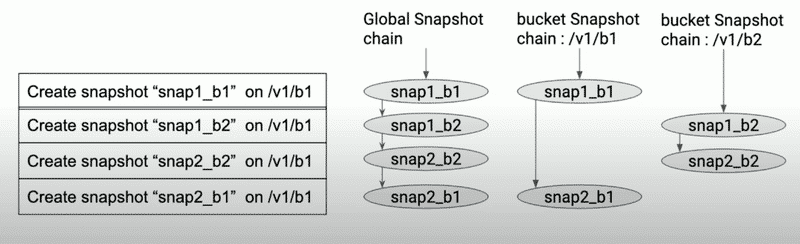
Ozone uses two types of snapshot chains to manage snapshots:
- global snapshot chain: all snapshots connected in chronological order, primarily used by system-level snapshot feature operations (Deep Clean, SST Filtering)
- path snapshot chain: each volume/bucket maintains its own snapshot chain (connected in chronological order), primarily used by Snapshot Diff
SnapshotChainInfo has previousSnapshotId and nextSnapshotId to maintain bidirectional links in the snapshot chain.
Snapshot Creation Process#
Pre-creation Validation#
- Validate snapshot name legality
- Check user permissions (only bucket owner and admin can create)
- Check snapshot count limit
- Generate snapshot ID (UUID)
RocksDB Checkpoint Creation#
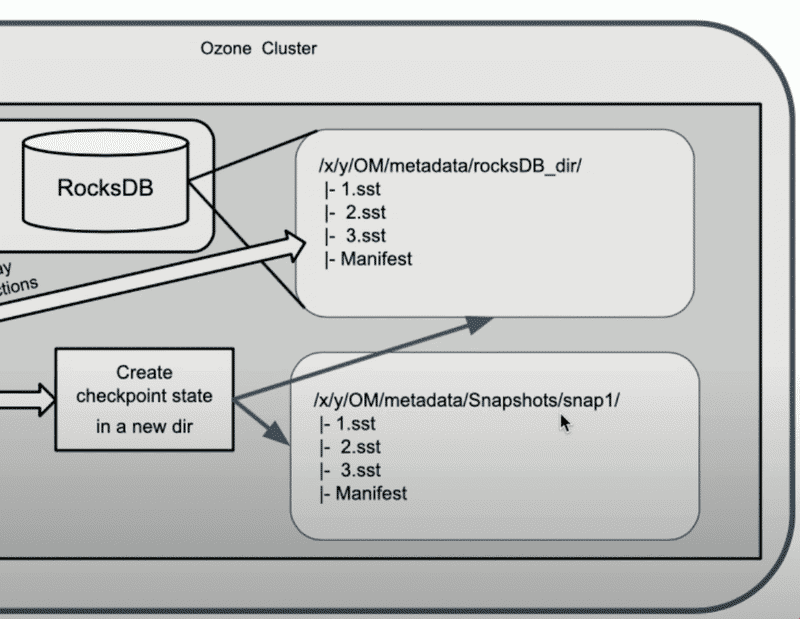
This is the core step of snapshot creation, utilizing RocksDB’s checkpoint feature:
Manually flush WAL and MemTable to disk, then call RocksDB’s create checkpoint API Since RocksDB Checkpoint is achieved by creating hard links to current SST Files, we need to force flush WAL and MemTable to disk to ensure SST Files contain the latest data.
Clean up deleted data within snapshot scope When Ozone deletes key or file, it doesn’t delete directly but records them in
deletedTableanddeletedDirectoryTable. During snapshot creation, since the contents ofdeletedTableanddeletedDirectoryTableare already recorded in the snapshot, these two tables can be cleared. This makes subsequent DeletingService/ReclaimableFilter easier to handle GC/Deep Clean, as doing so ensures each snapshot’sdeletedTable/deletedDirectoryTablecontents will never overlap, allowing them to be processed separately.
Lock Protection#
Locks are needed to protect against data races that might occur during snapshot creation:
- Read Lock on Bucket Lock to protect the bucket from deletion
- Write Lock on Snapshot Lock to protect the path snapshot chain
Also, snapshot creation must ensure atomicity to avoid partial success cases.
Since snapshot creation involves multiple components (Snapshot Chain Manager, Snapshot Info Table), if errors occur during the process, all changes need to be rolled back.
OzoneManagerLock#
We use a custom lock manager OzoneManagerLock for locking.
It consists of Striped Lock + Level Lock.
Striped Lock can manage locks for different keys individually, providing fine-grained locks to protect specific resources (like bucket prefix(volume1/bucket1), key prefix(volume1/bucket1/key1), etc.)
Striped<ReadWriteLock> stripedLock;Level Lock#
While Stripe Lock can provide fine-grained locks based on various bucket prefix/key prefix, this only solves concurrency issues between different resources. There’s another important issue to solve: operation order within the same thread and Resource Level Constraints.
For instance, for the prefix /volume1/bucket1, a thread might operate on multiple resource levels simultaneously:
- Bucket level: Modify bucket configuration, ACL, etc.
- Key level: Read/write keys within the bucket
- Snapshot level: Create or delete snapshots
Without level constraints, problems might arise:
// Wrong operation order: operate on key first, then bucket
lock.acquireWriteLock(KEY_PATH_LOCK, "volume1", "bucket1", "key1");
// Attempting to modify bucket config at this point might cause data inconsistency
lock.acquireWriteLock(BUCKET_LOCK, "volume1", "bucket1"); // Should throw exceptionSo we need Level Lock to determine which resources can successfully acquire locks within the same thread based on resource priority. Ozone’s defined resource priorities:
// For S3 Bucket need to allow only for S3, that should be means only 1.
S3_BUCKET_LOCK((byte) 0, "S3_BUCKET_LOCK"), // = 1
// For volume need to allow both s3 bucket and volume. 01 + 10 = 11 (3)
VOLUME_LOCK((byte) 1, "VOLUME_LOCK"), // = 2
// For bucket we need to allow both s3 bucket, volume and bucket. Which
// is equal to 100 + 010 + 001 = 111 = 4 + 2 + 1 = 7
BUCKET_LOCK((byte) 2, "BUCKET_LOCK"), // = 4
// For user we need to allow s3 bucket, volume, bucket and user lock.
// Which is 8 4 + 2 + 1 = 15
USER_LOCK((byte) 3, "USER_LOCK"), // 15
S3_SECRET_LOCK((byte) 4, "S3_SECRET_LOCK"), // 31
KEY_PATH_LOCK((byte) 5, "KEY_PATH_LOCK"), //63
PREFIX_LOCK((byte) 6, "PREFIX_LOCK"), //127
SNAPSHOT_LOCK((byte) 7, "SNAPSHOT_LOCK"); // = 255Level Lock is implemented using bit mask, each thread has its own independent lock state, and level constraints between different threads are mutually independent.
Through this design, we can ensure resource acquisition order is correct within the same thread, preventing deadlocks.
DeletingService & Deep Clean#
Ozone’s Deep Clean mechanism mainly relies on two background services: KeyDeletingService and DirectoryDeletingService. These services periodically scan OM metadata to safely reclaim and physically delete keys and directories that are marked for deletion but not yet reclaimed, based on snapshot chain status.
Deep Clean for Snapshots#
Ozone’s Deletion Service (including KeyDeletingService and DirectoryDeletingService) performs deep clean for every snapshot, not just the active DB (AOS). This is one of the core designs of Ozone’s snapshot space reclamation mechanism.
For example, the getTasks() method of DirectoryDeletingService automatically creates a background task for each snapshot (including active DB aka AOS).
A task queue is used to serially process each snapshot’s deep clean.
Similarly for KeyDeletingService.
The benefit of this design is: Each snapshot can perform deep clean independently, ensuring safe and efficient space reclamation even with long snapshot chains and complex data references between snapshots. Each snapshot’s deep clean status (like deepCleanedDeletedDir, deepCleanedDeletedKey) is tracked individually, and only marked as deep clean complete when all deleted directories or keys in that snapshot have been safely reclaimed.
This also means Ozone’s Deletion Service is not a “global one-time” cleanup but “individual processing for each snapshot”, which is a critical design for snapshot management in large-scale object storage systems.
KeyDeletingService#
It traverses snapshotRenamedTable and deletedTable, filters reclaimable keys using reclaimable filter, then sends them to SCM for physical deletion.
Traverse snapshotRenamedTable and deletedTable, filter reclaimable keys using reclaimable filter
During the process there are
remainNumandratisLimitdecrement counters used for pagination, limiting the total number of keys deleted at once and the total bytes number of data blocks respectively.Send to SCM for physical deletion (tell SCM which data blocks can be truly deleted, after deletion the entire file (metadata + data/content) truly disappears from the ozone cluster):
- Tell SCM which blocks can be deleted
- After SCM reports success, send purge keys request to OM, then keys are truly deleted from OM DB
When all keys in a snapshot have been safely reclaimed, update that snapshot’s deep clean marker
This indicates that snapshot’s keys have completed deep clean and space can be safely released later.
DirectoryDeletingService#
DirectoryDeletingService is responsible for reclaiming deleted directories (and all subdirectories and files within). It works similarly to KeyDeletingService, but with additional logic for recursively processing directory trees.
In Ozone Manager (OM)’s FSO (File System Optimized) mode, files and directories are actually mapped as tree structures in RocksDB tables. When a user deletes a directory, OM first writes the “deleted directory itself” to DeletedDirectoryTable, while the subdirectories and files underneath are not immediately moved away — this leaves the orphan directory cleanup problem.
DirectoryDeletingService is the background service specifically designed to handle these orphan directories:
- Recursive traversal and deletion: Traverse down to the leaves (subdirectories, subfiles), then delete the “empty directory” itself. (Here empty directory means a directory with no subdirectories or subfiles)
- Snapshot compatible: Ensures that any nodes still referenced by snapshots won’t be cleaned up prematurely.
- Batched and rate-limited: Also uses
ratisByteLimitfor pagination.
Recursive expansion process:
- List subdirectories → Put them back into DeletedDirectoryTable (Waiting for next round of processing, forming BFS-style expansion)
- List subfiles → Put them into DeletedTable
- If current directory has no child nodes → Add the “parent directory itself” to the deletion list, to be deleted together later.
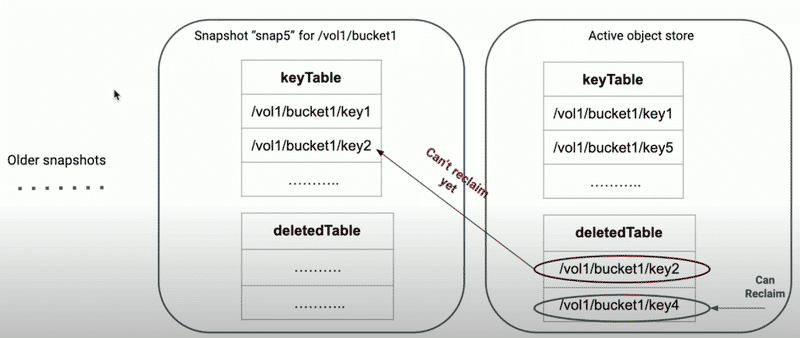
Reclaimable Filter#
What is Reclaimable Filter?#
As mentioned in the introduction:
When DeletingService submits data blocks for batch deletion to SCM, it can’t blindly submit everything. It needs to be Snapshot-Aware, filtering out data blocks owned by keys/files visible in snapshots to avoid deleting them, like filtering impurities
Reclaimable Filter is designed for this purpose - it filters which keys or directories can be reclaimed while DeletingService submits for batch deletion to SCM.
Actually there wasn’t originally a Reclaimable Filter, but the code here was really ugly, so Reclaimable Filter was used to encapsulate the Snapshot-Aware logic of DeletingService
ReclaimableFilter Abstract Class#
ReclaimableFilter provides a general framework for filtering reclaimable resources by snapshot.
You can specify checking N snapshots before the current snapshot, and ReclaimableFilter will automatically lock these snapshots and ensure snapshot chain consistency during each judgment. The specific reclamation judgment logic is implemented by various subclasses, while ReclaimableFilter itself only handles snapshot data preparation, locking, and resource management (explicitly close).
Logic of Various Reclaimable Filter Subclasses#
ReclaimableFilter has laid a good foundation for us. Now we just need to write the corresponding reclaimable logic for each type of resource.
ReclaimableKeyFilter#
Used to filter reclaimable file keys, needs to check the previous two snapshots:
public class ReclaimableKeyFilter extends ReclaimableFilter<OmKeyInfo> {
public ReclaimableKeyFilter(/* ... */) {
super(/* ... */, 2); // Need to check previous 2 snapshots
}
}- If this key cannot be found in the previous snapshot, it will be marked as “reclaimable”.
- If found in the previous snapshot, it will further check the “snapshot before the previous one” to confirm whether this key only exists in the previous snapshot, and count its size in the previous snapshot’s exclusive size statistics.
ReclaimableDirFilter#
Used to filter reclaimable directories, only needs to check the previous snapshot:
(Directory is one of Ozone’s Object Layouts - FileSystem Optimized. FSO layout has more efficient rename and delete performance. For details, see Prefix based File System Optimization)
public class ReclaimableDirFilter extends ReclaimableFilter<OmKeyInfo> {
public ReclaimableDirFilter(/* ... */) {
super(/* ... */, 1); // Only need to check previous 1 snapshot
}
}- If the previous snapshot doesn’t exist (e.g., snapshot has been deleted), this directory can be reclaimed directly.
- If the previous snapshot exists, query this directory’s info (
OmDirectoryInfo) in the previous snapshot:- If the directory cannot be found, it means the directory no longer exists in the previous snapshot and can be reclaimed.
- If found but with different
objectID, it means the directory has been overwritten or changed in the previous snapshot and can also be reclaimed. - Only when the previous snapshot has a directory with the same
objectIDcan it not be reclaimed.
ReclaimableRenameEntryFilter#
Used to filter reclaimable snapshot rename entries
What is rename entry?
When you rename a key/dir, if the bucket is within snapshot scope, to enable subsequent Snapshot Diff, GC/Deep Clean operations to correctly track this object’s history, a record is added to snapshotRenamedTable with the structure:
Key:/volumeName/bucketName/objectID(objectIDrepresents the unique ID of the renamed key or dir)Value: Key/dir path before rename
public class ReclaimableRenameEntryFilter extends ReclaimableFilter<String> {
public ReclaimableRenameEntryFilter(/* ... */) {
super(/* ... */, 1); // Only need to check previous 1 snapshot
}
}- If this objectId cannot be found in the previous snapshot, it means no one references this rename entry and can be reclaimed.
- If found, it means a snapshot still references this objectId and cannot be reclaimed.
Summary#
Killua
Actually, various Reclaimable Filters mainly just look at the previous snapshot’s data to determine if it’s reclaimable.
Only ReclaimableKeyFilter needs to look at one more snapshot to calculate the correct exclusive size.
Also, when you saw me mention above that as long as the key/dir/rename entry exists in the snapshot it cannot be reclaimed, you might think this implementation seems time-consuming, like checking each snapshot one by one, but if you think carefully using induction, you’ll realize we only need to look at the previous snapshot’s data to know which resources can be reclaimed and which cannot.
Conclusion#
Deep Clean is just a small part of Ozone Snapshot management. Actually, looking at the mechanisms mentioned in this article, they all seem like workarounds, giving the feeling that Ozone had to make compromises to implement snapshot features.
Reference#
- Snapshots for an Object Store
- Improving Snapshot Scale
- Ozone Snapshot Deletion & Garbage Collection
- Design: Ozone Snapshot Deletion Garbage Collection based on key deletedTable
Appendix#
AOS/AFS#
AOS stands for Active Object Store, AFS stands for Active File System. They actually refer to the normal RocksDB DB instance. This term exists mainly to distinguish from Snapshots.